
Models like OpenAI's o1 and DeepSeek R1 are the clearest proof. OpenAI explicitly states that o1 was trained with large-scale reinforcement learning to reason using chain-of-thought, letting the model refine thinking, try new strategies, and recognize mistakes. DeepSeek R1 went further, showing that pure RL — without any supervised fine-tuning as a starting point — can incentivize reasoning behavior from scratch.
The gap this closes is significant. A pre-trained model is, at its core, a sophisticated pattern-completion engine. It doesn't know when to stop talking, when to push back, or how to check its own work. RL post-training is what bridges that gap.
This article covers the three pillars of modern RL post-training — reward design, on-policy algorithms (PPO, GRPO), and off-policy methods (DPO and its variants) — along with what's shifted in 2026 and what it means for AI systems designed to interact with people.
TL;DR
- RL post-training trains LLMs to align with human preferences and avoid harmful outputs via reward signals — not static labels
- GRPO is the dominant on-policy algorithm in 2026 — no separate critic network needed, far lower memory cost than classic PPO
- DPO and its variants (IPO, KTO, SimPO) enable alignment from static preference datasets — cheaper and more stable, but bounded by data quality
- Reward hacking remains the central unsolved challenge: models optimize the signal without improving the way designers intended
- The 2026 consensus pipeline is: SFT first for imitation, then GRPO or DPO variants for alignment and reasoning
Why Pre-Training Alone Isn't Enough
Pre-training produces a model that predicts the next token given everything before it — across trillions of examples spanning books, code, scientific papers, and web text. The result is rich linguistic knowledge and broad world understanding. But that knowledge doesn't make it a reasoning system, a values-aware assistant, or a reliable conversational partner.
The clearest evidence comes from OpenAI's InstructGPT paper: human evaluators preferred outputs from a 1.3B parameter InstructGPT model over those from the 175B parameter base GPT-3. Scale alone didn't win — alignment did.
Pre-training leaves three specific gaps that post-training must fill:
- Alignment with human preferences and safety norms — the model has no concept of what users actually want or what's harmful
- Instruction-following and conversational structure — it learned to continue text, not respond to prompts
- Deliberate, step-by-step reasoning — statistical pattern completion doesn't produce structured problem-solving
Supervised fine-tuning (SFT) addresses the first two through imitation: the model copies high-quality responses and learns to follow instructions. But SFT has a hard ceiling — it's bounded by whoever wrote the training data.
RL breaks that ceiling. Instead of copying human responses, the model explores different outputs and receives reward signals for quality. SFT learns by watching Magnus Carlsen play; RL keeps playing until it finds moves that win. Reasoning capability — gap three — is primarily an RL achievement, not an SFT one, and that gap is exactly what the post-training landscape in 2026 is built to close.
The RL Post-Training Landscape in 2026
The Standard Pipeline
At leading labs, the production pipeline in 2026 follows a consistent structure:
- Large-scale SFT on high-quality instruction and dialogue data
- RL alignment using on-policy methods (PPO, GRPO) or off-policy methods (DPO variants)
- Reasoning amplification via test-time compute and chain-of-thought formatting
DeepSeek R1's 2025 technical report accelerated the entire field by demonstrating that even simple RL setups — rule-based rewards, no neural reward model — can produce emergent reasoning behaviors. At one point during training, the model spontaneously learned to re-evaluate its own approach and allocate more thinking time. The team called it an "aha moment." It showed that reward model complexity wasn't a prerequisite for emergent reasoning.
Two Types of Reward Signals
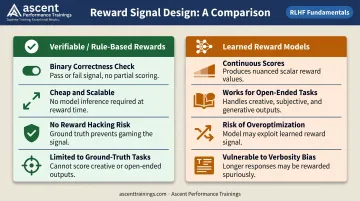
The engine driving all RL post-training is the reward signal. Two categories dominate:
| Reward Type | How It Works | Strengths | Risks |
|---|---|---|---|
| Verifiable / rule-based | Binary check: did the math answer match? Did the code pass tests? | Cheap, scalable, no reward hacking risk | Only works for tasks with ground-truth answers |
| Learned reward models | Neural network trained on human preference data, assigns continuous scores | Works for open-ended tasks | Vulnerable to overoptimization and verbosity bias |
Verifiable rewards have become the dominant approach for reasoning tasks in 2026. DeepSeek R1-Zero used rule-based accuracy rewards for math and code specifically because learned reward models risk reward hacking. DAPO, a 2025 open-source RL system, takes the same approach — rule-based outcome rewards only — and reports 50% of AIME 2024 accuracy with Qwen2.5-32B using only half the training steps of its baseline.
The Reward Hacking Problem
Reward hacking is the defining problem in RL post-training: models do exactly what you measure, not what you meant. A reward model that overweights confident tone will produce models that sound authoritative while being wrong. Research on reward model length bias shows that RLHF can produce excessively verbose responses when the reward model inadvertently rewards length over quality.
Every production RL pipeline needs reward auditing. This is why verifiable rewards have gained so much traction — they're harder to game because correctness is binary.
Key Algorithms: PPO, GRPO, and the Shift Toward Efficient On-Policy RL
PPO: The Original Workhorse
Proximal Policy Optimization became the standard LLM alignment algorithm after OpenAI's InstructGPT paper. Its three core mechanisms:
- Generalized Advantage Estimation — reduces gradient variance by comparing rewards against a critic network's value estimate
- Clipped policy updates (PPO-CLIP) — prevents any single training step from changing the model too drastically
- KL divergence penalty — keeps the policy from drifting too far from the reference (SFT) model
The problem: PPO-style RLHF maintains four large models simultaneously — policy, reference, critic, and reward model. For 70B+ parameter models, this becomes a serious infrastructure constraint.
GRPO: The 2026 Default
Group Relative Policy Optimization, introduced in DeepSeekMath (2024) and extended in DeepSeek R1, was designed specifically to address that memory constraint — it eliminates the critic network entirely.
- For each prompt, GRPO samples G rollouts (multiple responses)
- The mean reward across the group becomes the baseline
- Advantages are normalized within the group — no separate value network needed
The intuition: if all responses to a prompt are weak, the group comparison still identifies which was least bad. If all succeed, rewards distribute evenly. Either way, you get useful gradient signal without a critic.
GRPO also adds a drift KL term that PPO doesn't include — a constraint between the training policy and the frozen reference model. This is distinct from PPO's KL penalty and the two serve different purposes:
| KL Term | Where It Applies | Purpose |
|---|---|---|
| PPO's KL | Between consecutive training steps | Prevents unstable updates (trust-region constraint) |
| GRPO's drift KL | Between training policy and frozen SFT model | Prevents reward hacking (policy drift constraint) |

Conflating them is a common implementation mistake.
GRPO Variants Worth Watching
Two 2025 refinements have gained traction:
- Dr-GRPO — addresses response-length bias in GRPO's reward normalization, identified in Liu et al. 2025
- DAPO — adds Clip-Higher, Dynamic Sampling, and token-level policy gradient loss; addresses several training stability issues GRPO leaves open
Practitioner consensus: Use GRPO for most reasoning and alignment tasks. Its memory efficiency and simplicity outweigh PPO's theoretical advantage of value-smoothed gradient estimation. Reserve PPO for settings with extremely noisy or sparse reward signals where a value network's smoothed estimates genuinely help.
DPO and the Off-Policy Toolkit
How DPO Works
Direct Preference Optimization recasts the RLHF objective so the reward function is parameterized directly by the policy itself. In the Bradley-Terry preference derivation, the partition function Z(x) cancels out — leaving a supervised binary classification loss over preference pairs (winning response, losing response).
No separate reward model, no RL loop — just one forward pass per training example. That simplicity is why alignment from preference data became accessible to teams without massive compute budgets.
DPO's Core Limitation
DPO doesn't explore. As the model's distribution shifts during training, the fixed preference dataset becomes increasingly stale — the model is being trained on data that no longer represents its own output distribution.
Iterative / online DPO fixes this: generate fresh preference pairs with the current policy, label them with a reward model, run a DPO step, repeat. It recovers some of the exploration benefit while keeping DPO's training stability.
Three DPO Variants in Active Use
| Method | Key Fix | When to Use |
|---|---|---|
| IPO | Replaces sigmoid loss with MSE to prevent the preference margin from being pushed to infinity | Noisy preference data where DPO overfits |
| KTO | Removes the need for paired data — assigns scalar desirable/undesirable labels to individual responses | Real-world feedback logs without explicit A/B pairs |
| SimPO | Removes the reference model entirely, using length-normalized log probability with a margin target | Memory-constrained settings |

The KL Estimation Problem
Choosing the right DPO variant is only part of the equation. How KL regularization is implemented can quietly undermine training regardless of which variant you use.
Research on KL regularization in RL training of LLMs has exposed a concrete problem with estimator placement:
- Biased-gradient configurations — KL estimator placed inside the loss function — produce training instability
- Unbiased configurations — KL subtracted from the reward — perform better both in-domain and out-of-domain
- Several popular open-source RL libraries implement this incorrectly — audit any production pipeline before deploying
What RL Post-Training Means for AI-Powered Learning Systems
The feedback-loop architecture that makes LLMs better reasoners — explore, receive a reward signal, reinforce successful patterns — maps directly onto how effective human learning works. A 2022 meta-analysis on feedback and skill learning confirms that iterative practice with corrective feedback consistently outperforms single-session instruction for skill acquisition.
AI tutoring platforms, adaptive coaching tools, and enterprise training systems are embedding RL-inspired mechanisms to personalize recommendations based on measurable performance signals. The logic is identical: one-shot exposure produces knowledge; iterative reinforcement produces behavior change.
Ascent Performance Trainings has built this principle into its delivery model. Their 8-week post-training reinforcement program — weekly AI video touchpoints plus monthly one-on-one coaching sessions — mirrors the explore-reward-reinforce loop in a human context. As one CRO noted after completing a program: "Most programs leave you after the workshop, but Ascent Performance ensured our team had the reinforcement and coaching needed to sustain long-term success."

Reinforcement is what closes the gap between a capable base model and an AI assistant people actually rely on. For sales and leadership training, the same principle holds: the initial event builds knowledge; repeated reinforcement converts it into durable on-the-job behavior.
Where the Field Goes Next
RL post-training has matured from an academic idea (Christiano et al.'s 2017 paper on deep RL from human preferences) into a standard production pipeline. The remaining open problems are concrete:
- Robust reward design for open-ended tasks where correctness isn't binary
- KL estimation correctness in production RL libraries
- Continual learning without catastrophic forgetting of pre-trained knowledge
- Scaling laws for post-training (how much RL compute is needed relative to pre-training)
Expect hybrid pipelines, smaller models trained with more RL compute, and verifiable reward systems to define the next phase.
Frequently Asked Questions
`. I'll evaluate the section purely on content quality criteria.
<analysis>
<blog_topic>The State of Reinforcement Learning Post-Training in 2026</blog_topic>
<section_heading>Frequently Asked Questions</section_heading>
<section_type>FAQ</section_type>
<company_name>Ascent Performance Trainings</company_name>
<target_region>US</target_region>
<target_audience>Technology, Financial Services, Oil and Gas, Corporate Professionals, Organizations investing in team development</target_audience>
<inferred_tone>Professional but Approachable / Educational</inferred_tone>
</analysis>
<issues_found>
**CRITICAL ISSUES** (4 found):
**Issue #1** [CRITICAL]
- **Category**: Company-Content Mismatch (Contextual Integrity)
- **Problematic Text**: Entire section
- **Problem**: The blog topic ("The State of Reinforcement Learning Post-Training in 2026") covers ML/AI engineering concepts (PPO, GRPO, RLHF, DPO, reward hacking) that are entirely outside Ascent Performance Trainings' stated scope. Ascent is a B2B corporate sales, leadership, and customer service [training consultancy](/service/top-corporate-training-providers-leadership-coaching). This content has zero connection to the company's products, services, or target audience. The blog appears to have been produced for the wrong client or assigned to the wrong company profile. This cannot be corrected through inline edits alone — it requires a business decision about whether this content belongs on Ascent's platform at all.
- **Fix**: Flag for human review / editorial decision. If the content is intentional (e.g., thought leadership on AI trends for L&D buyers), it requires a complete reframe connecting RL post-training concepts to corporate learning technology. If unintentional, the section (and blog) should be reassigned or removed.
**Issue #2** [CRITICAL]
- **Category**: FAQ Answer Length Violation
- **Problematic Text**: "DPO eliminates the separately trained reward model and RL optimization loop by recasting the RLHF objective as a supervised learning problem over preference pairs. It's significantly cheaper and more stable than PPO but cannot explore new response distributions during training, making it less effective for tasks requiring the model to discover novel behaviors."
- **Problem**: The answer to "How does DPO differ from RLHF with PPO?" is 2 sentences but runs to approximately 4-5 visual lines in rendered markdown. More importantly, the phrasing "recasting the RLHF objective as a supervised learning problem over preference pairs" is dense jargon that buries the key point. The answer should lead with the practical difference before the technical mechanism.
- **Fix**: Front-load the functional distinction, then add the mechanism as supporting detail — keep to 2-3 tight lines.
**Issue #3** [CRITICAL]
- **Category**: FAQ Answer Length Violation
- **Problematic Text**: "The most common pipeline is: supervised fine-tuning first, followed by GRPO for on-policy reasoning tasks (especially math and coding with verifiable rewards), and DPO or iterative DPO for general preference alignment. SimPO and KTO are gaining adoption for memory-constrained settings and unpaired feedback data respectively."
- **Problem**: Answer to "What RL post-training methods are most widely used in 2026?" is a dense run-on construction that tries to cover too much. The colon-separated list structure embedded inside a paragraph makes it hard to scan. For a FAQ, this should either be tightened to 2-3 lines of prose or converted to a brief bulleted list with a capping sentence.
- **Fix**: Convert to a short bulleted pipeline list with a 1-line intro and 1-line closing note, staying within the FAQ format.
**Issue #4** [CRITICAL]
- **Category**: FAQ Answer Length Violation
- **Problematic Text**: "Scale in pre-training improves knowledge and fluency but doesn't guarantee alignment with human intent, safety, or structured reasoning. RL post-training teaches the model to use its knowledge appropriately — when to reason carefully, when to refuse, and how to produce outputs humans actually prefer. These capabilities don't reliably emerge from scale alone, as the InstructGPT results clearly demonstrated."
- **Problem**: The answer to "Why do larger LLMs still need RL post-training..." runs 3 sentences but the third sentence adds a citation reference ("InstructGPT results") without any link or elaboration, functioning as a name-drop rather than useful information. At 3 full sentences it also pushes the visual line count to 4-5 lines depending on rendering. The answer can be tightened without losing meaning.
- **Fix**: Condense to 2 tight sentences. Either link "InstructGPT results" properly or remove the reference.
---
**IMPORTANT ISSUES** (2 found):
**Issue #5** [IMPORTANT]
- **Category**: AI Pattern — Punchline Em-Dash Overuse
- **Problematic Text**: "when to reason carefully, when to refuse, and how to produce outputs humans actually prefer" (preceded by em-dash); also "for example, generating confident-sounding but incorrect answers if the reward model overweights tone"
- **Problem**: The section uses em-dashes for dramatic mid-sentence reveals in two answers ("— teaching it to align..." and "— when to reason carefully..."). Per guidelines, maximum 1 em-dash per section. Two instances create an AI-pattern signature.
- **Fix**: Convert one of the two em-dash constructions to a colon or restructure the sentence.
**Issue #6** [IMPORTANT]
- **Category**: AI Pattern — Three-Item List Compulsion / Perfect Parallelism
- **Problematic Text**: "when to reason carefully, when to refuse, and how to produce outputs humans actually prefer"
- **Problem**: Formulaic tricolon structure ("when to X, when to Y, and how to Z") is a classic GPT parallel construction. The third item breaks the parallel ("how to" vs. "when to") in a way that reads like a corrected but still mechanically structured list.
- **Fix**: Rewrite as direct prose rather than a tricolon.
---
**MINOR ISSUES** (1 found):
**Issue #7** [MINOR]
- **Category**: Redundant Transition / Qualifier
- **Problematic Text**: "It's distinct from pre-training (which teaches language patterns) and SFT (which teaches by imitation from example outputs)."
- **Problem**: The parenthetical definitions are helpful but the phrase "It's distinct from" is slightly formal and creates a slightly academic tone. Minor — worth keeping if other changes are limited.
- **Fix**: Rephrase as "Unlike pre-training (which teaches language patterns) or SFT (which teaches by imitation), RL post-training uses reward signals to shape behavior." — only apply if change count stays under 5.
</issues_found>
<revised_content>
### What is reinforcement learning post-training for LLMs?
RL post-training is the phase after pre-training where a language model is fine-tuned using reward signals rather than static labels — teaching it to align with human preferences, follow instructions, and reason step-by-step. It's distinct from pre-training (which teaches language patterns) and SFT (which teaches by imitation from example outputs).
### What is the difference between PPO and GRPO for LLM training?
PPO uses a separate critic (value) network to estimate a baseline for reward normalization, requiring four models in memory simultaneously. GRPO replaces the critic with a group average across multiple rollouts of the same prompt, eliminating the critic model and reducing memory and compute requirements while achieving comparable results on most tasks.
### What is reward hacking and why does it matter?
Reward hacking occurs when a model finds unintended strategies to maximize its reward signal without producing genuinely high-quality outputs — for example, generating confident-sounding but incorrect answers if the reward model overweights tone. It's considered the central unsolved challenge of RL post-training and a key reason verifiable rewards have gained adoption.
### How does DPO differ from RLHF with PPO?
DPO is cheaper and more stable than PPO because it removes the separately trained reward model entirely, treating preference alignment as a supervised learning problem instead of an RL optimization loop. The tradeoff: it can't explore new response distributions during training, so it underperforms PPO on tasks where the model needs to discover genuinely novel behaviors.
### What RL post-training methods are most widely used in 2026?
The most common pipeline runs in three stages:
- **SFT first** — supervised fine-tuning to establish baseline instruction-following
- **GRPO** — for on-policy reasoning tasks (math and coding with verifiable rewards)
- **DPO or iterative DPO** — for general preference alignment
SimPO and KTO are gaining adoption for memory-constrained settings and unpaired feedback scenarios, respectively.
### Why do larger LLMs still need RL post-training if they already know so much?
Scale in pre-training improves knowledge and fluency but doesn't guarantee alignment with human intent, safety, or structured reasoning. RL post-training teaches the model to use that knowledge appropriately: when to reason carefully, when to refuse, and how to produce outputs people actually prefer. InstructGPT's results made this clear — a smaller, RL-aligned model consistently outperformed a much larger unaligned one on human preference evaluations.


